基本介绍
Onlinemeta 是一个基于 Shiny 的网络工具,它包括用户界面 (UI) 和服务器功能(Server)。
对于 UI 部分,主题使用 R 包“shinydashboard”,数据框显示使用 R 包“DT”,介绍界面使用 R 包“SlickR”和“ShinyLP”。对于服务器部分,风险偏差分析使用 R 包“ComplexHeatmap”、“robvis”、“colourpicker”、“ggpubr”和“RColorBrewer”,而荟萃分析使用 R 包“meta”、“metamisc”和“mada”。整个界面优化使用 R 包“ShinyJS”、“ShinyDisconnect”、“ShinyFeedback”和“Reactable”。图像可以导出为 PDF 或 PNG。该网络工具可以在地址 https://smuonco.Shinyapps.io/Onlinemeta/ 找到,无需登录即可免费使用
用到的R包介绍(可视化美化部分)
RColorBrewer
RColorBrewer 是一个 R 语言中常用的用于创建颜色调色板的包。它提供了一系列优质的、预定义的颜色调色板,可以用于数据可视化、绘图等各种应用场景。RColorBrewer 的功能作用主要包括以下几点:
提供了多种颜色调色板:RColorBrewer 提供了多种类型的颜色调色板,包括顺序型、发散型和定性型。这些调色板可以根据数据的特点选择合适的颜色序列,有助于增强图表的可读性和视觉效果。
适用于不同类型的数据:RColorBrewer 的颜色调色板可以用于不同类型的数据可视化,包括连续型数据、离散型数据和发散型数据。用户可以根据需要选择合适的调色板类型和颜色数量。
易于使用:RColorBrewer 提供了简单易用的接口,用户可以通过几行代码轻松地创建颜色调色板,并将其应用于绘图和数据可视化中。调色板的使用方式灵活多样,可以直接指定调色板的名称,也可以自定义颜色数量和颜色范围。
支持自定义:除了预定义的颜色调色板外,RColorBrewer 还支持用户自定义颜色调色板。用户可以根据自己的需求定义新的颜色序列,或者调整现有调色板的参数,以满足特定的数据可视化需求。
总的来说,RColorBrewer 提供了丰富多样的颜色调色板,并且易于使用,适用于各种数据可视化和绘图任务,是 R 语言中常用的绘图工具之一。
colourpicker
colourpicker 是 R 语言中的一个包,用于创建交互式的颜色选择器,可以让用户通过图形界面选择颜色,而不必手动输入颜色代码。它的主要功能和作用包括:
交互式颜色选择:
colourpicker提供了一个交互式的颜色选择器,用户可以通过拖动滑块或者直接点击颜色面板来选择颜色,而不必手动输入颜色代码。支持多种颜色格式:
colourpicker支持多种颜色格式,包括十六进制(Hexadecimal)、RGB、HSL 等,用户可以根据需要选择合适的颜色表示方式。集成于 Shiny 应用:
colourpicker可以很容易地集成到 Shiny 应用中,作为交互式组件,使得用户能够在 Shiny 应用中动态选择颜色。自定义选项:
colourpicker提供了多种自定义选项,包括颜色面板的大小、默认颜色、颜色空间等,用户可以根据自己的需求进行定制。方便的调用接口:
colourpicker提供了简单易用的函数接口,用户可以很方便地在 R 脚本中调用颜色选择器,而无需编写复杂的代码。跨平台支持:
colourpicker支持在 Windows、Mac OS 和 Linux 等多种操作系统上运行,具有较好的跨平台兼容性。
总的来说,colourpicker 包提供了一个方便易用的颜色选择器,能够帮助用户快速选择颜色,并集成到 Shiny 应用中,为用户提供更丰富的交互体验。
colorspace
colorspace 是 R 语言中的一个包,用于在不同的颜色空间中进行颜色操作和转换。它提供了一系列函数,可以帮助用户处理和分析各种颜色数据,并进行颜色空间的转换、调整和操作。colorspace 的主要功能和作用包括:
颜色空间转换:
colorspace支持将颜色表示在不同的颜色空间中,包括 RGB、HSL、HSV、Lab 等,用户可以方便地在这些颜色空间之间进行转换,以满足不同的需求。颜色调整:
colorspace提供了一系列函数,可以对颜色进行调整,比如调整亮度、饱和度、对比度等,以及应用颜色渐变和滤镜效果,使得用户可以灵活地修改和优化颜色。颜色操控:
colorspace提供了丰富的颜色操作函数,包括颜色混合、插值、反转等,可以帮助用户对颜色进行复杂的操作和操控,实现更多样化的颜色效果。色彩空间理论:
colorspace提供了颜色空间理论的支持,包括常见的色彩模型、色彩空间的概念和计算方法等,使得用户可以更深入地了解和应用色彩学理论。数据可视化:
colorspace支持在数据可视化中使用各种颜色空间和颜色调色板,帮助用户生成优美的图形和图像,提升数据可视化效果。
总的来说,colorspace 包提供了丰富的颜色操作和转换功能,可以帮助用户处理和分析各种颜色数据,实现更加丰富和多样化的颜色效果。
slickR
slickR 是一个 R 包,用于在 Shiny 应用程序中创建交互式的轮播图(carousel)。其主要功能和作用包括:
创建轮播图:
slickR允许您在 Shiny 应用程序中创建各种类型的轮播图,包括图片轮播、文本轮播等。您可以通过简单的 R 代码定义轮播图的内容和样式。交互式功能:轮播图通过鼠标滚动或点击按钮等方式实现交互式操作,用户可以自由浏览和切换轮播图中的内容。
自定义样式:
slickR提供了许多可定制的选项,您可以根据需要调整轮播图的样式、布局、尺寸等,以适应应用程序的设计需求。响应式设计:轮播图可以根据不同的屏幕尺寸和设备自动调整布局和大小,以确保在各种设备上都能够正常显示和使用。
与 Shiny 应用程序集成:
slickR可以与 Shiny 应用程序无缝集成,您可以将轮播图嵌入到 Shiny 应用程序的 UI 中,并与其他元素和功能进行交互。
总的来说,slickR 提供了一个简单而强大的工具,用于在 Shiny 应用程序中创建吸引人的交互式轮播图,帮助您向用户展示内容并提升用户体验。
shinycssloaders
shinycssloaders 是 R 语言中的一个包,用于在 Shiny 应用中添加各种 CSS 动画加载器(loading spinner)来增强用户体验。它提供了一系列现成的 CSS 加载器样式,可以方便地集成到 Shiny 应用中,用于在数据加载、计算或其他长时间操作时显示加载状态,以提醒用户应用正在处理任务。
shinycssloaders 的功能和作用包括:
提供多种加载器样式:
shinycssloaders提供了多种现成的 CSS 加载器样式,包括旋转加载器、波浪加载器、脉冲加载器等,用户可以根据自己的喜好和需求选择合适的样式。简单易用:集成
shinycssloaders到 Shiny 应用中非常简单,只需要通过函数调用指定加载器样式和相关参数即可,无需编写复杂的 CSS 代码。提升用户体验:通过显示加载状态,用户可以清楚地知道应用正在处理任务,避免因等待而感到焦虑或不耐烦,从而提升用户体验和应用的友好度。
自定义加载器样式:除了提供现成的加载器样式外,
shinycssloaders还支持用户自定义加载器样式,用户可以根据自己的需求定义新的加载器样式,以满足特定的应用场景。可扩展性:
shinycssloaders提供了灵活的选项和参数,可以轻松地与其他 Shiny 插件和扩展集成,使得用户可以根据需要扩展加载器的功能和样式。
总的来说,shinycssloaders 是一个方便实用的包,可以帮助 Shiny 应用开发者在应用中添加各种加载器样式,提升用户体验和应用的交互效果。
shinydisconnect
shinydisconnect 是一个 R 包,用于在 Shiny 应用程序中处理用户断开连接(disconnect)的情况。其主要功能和作用包括:
监测连接状态:shinydisconnect 可以监测用户与 Shiny 应用程序之间的连接状态。当用户断开连接时,shinydisconnect 可以捕获这种情况并触发相应的事件。
处理断开连接事件:shinydisconnect 允许您定义用户断开连接时要执行的操作。例如,您可以显示警告消息、保存应用程序状态、记录用户操作日志等。
自定义提示信息:shinydisconnect 允许您自定义用户断开连接时显示的提示信息。这样可以提高用户体验,并提示用户重新连接或采取其他措施。
处理重新连接:shinydisconnect 还可以处理用户重新连接的情况。您可以定义重新连接时要执行的操作,以恢复应用程序的状态和功能。
与其他功能集成:shinydisconnect 可以与 Shiny 应用程序的其他功能无缝集成,如用户认证、会话管理、数据存储等。这样可以提高应用程序的稳定性和可靠性。
总的来说,shinydisconnect 提供了一种方便而有效的方式来处理用户断开连接的情况,帮助您确保 Shiny 应用程序在各种网络环境下都能够正常运行并提供良好的用户体验。
用到的R包介绍(优化部分)
ggpubr
ggpubr 是 R 语言中的一个包,主要用于在基于 ggplot2 的图形基础上进行进一步的美化、调整和注释,以生成出版品质的图形。它提供了一系列函数和工具,能够方便地对 ggplot2 图形进行修改和增强。ggpubr 的功能和作用包括:
美化图形:
ggpubr提供了一系列易用的函数,用于调整图形的主题、标题、标签、字体、颜色、线条类型等,使得图形更加美观和易读。添加统计信息:
ggpubr提供了多种函数,可以方便地添加统计信息,比如均值、标准差、置信区间等,帮助读者更好地理解数据。批量绘图:
ggpubr支持批量绘制多个图形,并将它们组织在一个图形区域中,从而方便比较不同数据之间的关系。生成出版品质的图形:
ggpubr的设计初衷就是为了生成出版品质的图形,因此它提供了大量的参数和选项,能够满足不同需求,生成高质量的出版物图形。支持复杂的图形布局:
ggpubr支持在一个图形中同时展示多个图形,比如散点图和线图的组合,箱线图和小提琴图的组合等,使得复杂数据的展示更加清晰。批量保存图形:
ggpubr提供了方便的函数,可以批量保存图形为多种常见格式,比如 PDF、PNG、JPEG 等,方便后续的出版和分享。
总的来说,ggpubr 是一个功能强大、易用的 R 包,可以帮助用户轻松生成出版品质的图形,并进行必要的美化和注释。
reshape2
reshape2 是 R 语言中的一个包,用于数据重塑(data reshaping)和数据变换(data transformation)。它提供了一系列函数,可以方便地对数据进行重塑、整理和转换,使数据更适合于分析、可视化和建模。reshape2 的主要功能和作用包括:
数据重塑(Data Reshaping):
reshape2提供了melt()和dcast()等函数,可以将宽格式(wide format)的数据转换为长格式(long format)或者将长格式的数据转换为宽格式。这种数据重塑操作有助于更好地理解和分析数据,特别是对于需要进行聚合分析或者可视化的情况。数据整理(Data Aggregation):通过
melt()函数,reshape2可以将数据进行汇总、聚合和整理,生成适合进行分组统计或者绘图的数据格式。这样可以更方便地对数据进行分析和展示。数据变换(Data Transformation):
reshape2提供了一系列用于数据变换的函数,比如acast()、cast()、colsplit()等,可以对数据进行透视、转置、列拆分等操作,从而使数据更符合分析需求。数据准备(Data Preparation):在进行数据分析之前,通常需要对数据进行清洗、准备和预处理。
reshape2提供了一些方便的函数,可以帮助用户快速地准备数据,包括去除重复值、处理缺失值、变量重命名等操作。
总的来说,reshape2 包提供了一系列方便实用的函数,可以帮助用户对数据进行重塑、整理和转换,从而更好地进行数据分析和建模。
shinyFeedback
shinyFeedback 是一个 R 包,用于在 Shiny 应用程序中实现实时反馈和验证。其主要功能和作用包括:
实时反馈:
shinyFeedback允许您在用户输入数据时提供实时反馈。您可以根据用户的输入动态更改应用程序中的元素,例如文本颜色、边框颜色、图标等,以向用户显示输入是否有效。输入验证:您可以使用
shinyFeedback来验证用户的输入数据。它提供了一组验证函数,可用于检查输入是否符合预期的格式、范围或其他标准。如果输入无效,可以向用户显示错误消息以指导他们进行更正。交互式表单:通过与
shinyFeedback结合使用,您可以创建交互式表单,用户在填写表单时会得到及时的反馈和验证。这可以提高用户体验,并减少数据输入错误的可能性。自定义样式:
shinyFeedback允许您根据应用程序的设计需求自定义反馈消息和验证样式。您可以更改消息的颜色、字体、大小等,以及验证失败时元素的外观。
总的来说,shinyFeedback 提供了一种简单而强大的方式,使 Shiny 应用程序更加交互式和用户友好,使用户能够更轻松地与应用程序交互,并提供有用的反馈来指导他们正确地使用应用程序。
XML
XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,其主要功能和作用包括:
数据存储和交换:XML 提供了一种通用的数据格式,可以用于存储和交换各种类型的数据,包括文本、图像、音频、视频等。它是一种非常灵活的格式,可以适应不同类型和结构的数据。
数据描述:XML 允许您使用自定义的标签和属性来描述数据的结构和语义。这使得数据可以更容易理解和解释,并且具有良好的可读性。
数据验证:XML 提供了一种验证机制,可以使用 Document Type Definition (DTD)、XML Schema 或 Relax NG 等方式对 XML 文档的结构和内容进行验证,以确保其符合预期的格式和规范。
数据传输:XML 是一种纯文本格式,可以在各种平台和环境中进行传输,包括网络、文件系统、数据库等。它也支持压缩和加密等技术,以确保数据的安全性和完整性。
数据处理:XML 提供了许多处理工具和技术,可以对 XML 文档进行解析、查询、转换、合并等操作。这使得 XML 成为一种非常强大和灵活的数据处理工具。
总的来说,XML 是一种通用的数据格式,具有灵活性、可读性和可扩展性等特点,适用于各种不同的应用场景,包括 Web 开发、数据交换、配置文件、文档存储等。
shinyLP
shinyLP 是一个 R 包,用于在 Shiny 应用程序中创建基于 Bootstrap 的单页面应用程序(Single-Page Applications,SPA)。其主要功能和作用包括:
单页面应用程序:shinyLP 允许您创建单页面应用程序,其中所有的交互和导航都在同一个页面上进行,而不需要加载新的页面。这种设计可以提高用户体验,并减少页面加载时间。
基于 Bootstrap:shinyLP 使用 Bootstrap 框架来实现页面布局和样式,因此您可以轻松创建具有现代和响应式设计的应用程序。
模块化设计:shinyLP 支持将应用程序拆分为多个模块,每个模块可以独立开发和维护。这样可以使应用程序更易于管理和扩展。
交互式组件:shinyLP 提供了许多交互式组件,如表格、图表、表单等,可以帮助您实现各种功能和特性,如数据展示、用户输入、数据过滤等。
自定义主题:shinyLP 允许您自定义应用程序的主题和样式,包括颜色、字体、边框等,以适应不同的设计需求和品牌风格。
总的来说,shinyLP 提供了一个简单而强大的工具,用于创建现代化的单页面 Shiny 应用程序,帮助您快速搭建交互式和响应式的 Web 应用。
shinyjs
shinyjs 是一个 R 包,用于在 Shiny 应用程序中轻松地添加 JavaScript 功能。其主要功能和作用包括:
操作 HTML 元素:shinyjs 允许您使用 R 代码操作和控制 Shiny 应用程序中的 HTML 元素,包括隐藏、显示、禁用、启用、添加和移除元素等。
执行 JavaScript 代码:shinyjs 提供了一个函数来执行自定义的 JavaScript 代码。这使得您可以在 Shiny 应用程序中使用 JavaScript 来实现各种高级功能和交互效果。
显示和隐藏元素:您可以使用 shinyjs 来动态显示和隐藏页面中的元素,如侧边栏、模态框、提示框等。这样可以根据用户的操作和条件来动态调整页面布局和内容。
执行动画效果:shinyjs 支持一些常见的动画效果,如淡入淡出、滑动、缩放等。这些效果可以使页面更加生动和吸引人。
与 Shiny 交互:shinyjs 可以与 Shiny 应用程序的其他功能无缝集成,如响应式数据分析、交互式图表等。您可以使用 shinyjs 来与 Shiny 服务器端交互,实现更丰富的用户体验。
总的来说,shinyjs 提供了一个简单而强大的工具,用于在 Shiny 应用程序中添加 JavaScript 功能,帮助您实现更多样化、交互性更强的 Web 应用程序。
用到的R包介绍(基石部分)
shiny
multinma
“multinma” 是一个用于在 Stan 中进行网络荟萃分析(Network Meta-Analysis)的 R 包。它的功能包括:
- 网络荟萃分析(NMA):将多个研究中关于多种治疗方法的(聚合)数据组合起来,以产生关于网络中每对治疗方法的相对治疗效果的一致估计。
- 网络荟萃回归(NMR):将 NMA 扩展到包括协变量,允许在研究之间调整效应修饰变量的差异。NMR 通常使用聚合数据(AgD)进行,这种数据缺乏力量,并且容易出现生态偏倚。如果数据可用,NMR 使用个体患者数据(IPD)是最佳选择。
- 多层次网络荟萃回归(ML-NMR):允许将 IPD 和 AgD 结合在一起进行网络荟萃回归。在 ML-NMR 模型中,定义一个个体级别的回归模型。然后,通过在各自的协变量分布上积分来拟合 AgD 研究。这样可以正确地链接模型的两个级别,避免聚合偏差。ML-NMR 可以为网络中的任何研究人群或外部目标人群产生人群调整后的治疗效果。
“multinma” 使用贝叶斯框架在 Stan 中估计模型,并使用基于 Sobol’ 序列的拟蒙特卡洛数值积分进行 ML-NMR 模型中的积分,使用高斯 copula 来考虑协变量之间的相关性。
开始使用 “multinma” 包的好方法是查看包的文档,特别是包中的示例分析。另外,英国国家卫生与临床卓越中心(National Institute for Health and Care Excellence, NICE)的技术支持文件系列提供了有关证据综合的详细介绍。多层次网络荟萃回归的方法已经在相关的方法论文中描述。
shinydashboard
shinydashboard 是 R 语言中的一个包,用于创建基于 Shiny 的仪表板应用。它提供了一套丰富的 UI 组件和布局选项,可以帮助用户快速构建具有仪表板风格的交互式应用。shinydashboard 的主要功能和作用包括:
创建仪表板布局:
shinydashboard提供了多种布局选项,包括侧边栏(sidebar)、头部导航栏(header)、主体内容区域(body),以及选项卡式导航等,可以根据需要灵活配置页面布局。丰富的 UI 组件:
shinydashboard集成了大量的 UI 组件,包括信息框(infoBox)、值框(valueBox)、图表框(box)、进度条(progress bar)等,这些组件可以帮助用户快速构建具有丰富交互功能的仪表板页面。自定义主题:
shinydashboard允许用户自定义仪表板的主题样式,包括颜色、字体、背景等,使得用户可以根据自己的品牌风格或者应用需求定制独特的主题。交互式组件:
shinydashboard支持集成 Shiny 的交互式组件,比如下拉菜单、滑块、复选框等,用户可以通过这些组件与应用进行交互,并实时更新仪表板内容。动态数据可视化:
shinydashboard结合了 Shiny 和 Plotly、Highcharts 等数据可视化包,可以创建动态、交互式的图表和数据可视化组件,使得用户可以实时探索和分析数据。支持响应式布局:
shinydashboard支持响应式设计,可以在不同大小的屏幕上自动调整布局,保证应用在各种设备上的良好显示效果。
总的来说,shinydashboard 是一个功能强大、灵活易用的包,适用于创建各种类型的仪表板应用,包括数据分析、监控报告、数据仪表盘等,为用户提供了丰富的 UI 组件和布局选项,帮助用户快速构建具有专业品质的仪表板应用。
reactable
reactable 是 R 语言中的一个包,用于创建交互式的表格组件,支持在 Shiny 应用和 R Markdown 文档中展示数据表格,并提供了丰富的交互功能和定制选项。reactable 的主要功能和作用包括:
创建交互式表格:
reactable可以帮助用户轻松创建交互式的数据表格,包括排序、过滤、分页、搜索等功能,使得用户可以方便地浏览和查找数据。支持大型数据集:
reactable能够高效地处理大型数据集,支持对数千行甚至数十万行数据进行展示和操作,保证了在大规模数据集下的流畅体验。丰富的交互功能:除了基本的排序、过滤和搜索功能外,
reactable还支持自定义列格式、单元格样式、条件格式化等高级交互功能,使得用户可以根据需要定制表格的外观和行为。支持 Shiny 应用:
reactable可以很方便地集成到 Shiny 应用中,作为交互式组件使用,与其他 Shiny 组件和事件进行交互,实现复杂的数据分析和可视化功能。支持 R Markdown 文档:
reactable支持在 R Markdown 文档中使用,以 HTML 表格的形式展示数据,提供了丰富的选项和参数,可以定制表格的外观和交互效果。易于定制和扩展:
reactable提供了丰富的选项和参数,可以定制表格的各种属性,包括列名、列宽、排序方式等,同时还支持通过 CSS 和 JavaScript 进行定制和扩展。
总的来说,reactable 是一个功能强大、灵活易用的表格组件,适用于在 Shiny 应用和 R Markdown 文档中展示数据表格,并提供了丰富的交互功能和定制选项,帮助用户创建专业水平的数据表格展示和交互体验。
robvis (meta相关)
robvis 是 R 语言中的一个包,用于进行元分析(meta-analysis)中的异质性检验和敏感性分析。它提供了一系列函数和工具,可以帮助用户评估元分析结果的稳健性和可靠性,以及发现可能的异质性源和敏感性问题。robvis 的主要功能和作用包括:
异质性检验:
robvis提供了多种常用的异质性检验方法,包括 Cochran’s Q 统计量、I² 统计量等,可以帮助用户评估元分析结果中的异质性程度。敏感性分析:
robvis支持进行敏感性分析,包括排除异常研究、逐步排除研究、子组分析等方法,以评估元分析结果对个别研究的依赖程度和对结果的稳健性。绘图功能:
robvis提供了绘制元分析结果的函数,包括森林图(forest plot)、漏斗图(funnel plot)等,可视化展示元分析效应量和置信区间,帮助用户直观地理解研究间的异质性和可能的偏倚。结果导出:
robvis支持将元分析结果导出为各种格式,包括图片(PNG、JPEG)、矢量图(PDF、SVG)等,方便用户在论文或报告中使用。丰富的文档和示例:
robvis提供了详细的文档和示例,包括函数使用说明、案例分析和代码示例,帮助用户快速上手和理解如何使用包中的功能进行元分析的异质性检验和敏感性分析。
总的来说,robvis 是一个强大的元分析工具包,提供了丰富的功能和工具,可以帮助用户进行元分析结果的异质性检验和敏感性分析,评估结果的稳健性和可靠性,为研究者提供了一个重要的分析工具。
metamisc (meta相关)
metamisc 是 R 语言中的一个包,提供了一些辅助性的函数和工具,用于辅助元分析(meta-analysis)和系统评价(systematic review)的数据处理和分析。虽然该包的功能相对较少,但它仍然提供了一些有用的函数,例如:
trim()函数:用于修剪数据集中的异常值或极端值。这可以帮助提高元分析的稳健性和可靠性。mcarray()函数:用于创建元分析的 Monte Carlo 数组。这对于进行敏感性分析和模拟研究结果非常有用。smr()函数:用于计算标准化死亡比率(Standardized Mortality Ratio)。这在一些研究中是非常重要的指标。
虽然 metamisc 包的功能有限,但它仍然可以作为辅助工具,在一些特定的元分析和系统评价项目中发挥一定的作用。
data.table
data.table 是 R 语言中一个功能强大的数据处理包,它提供了高效的数据处理和操作功能,特别适用于大型数据集的处理和分析。data.table 包的主要功能和作用包括:
数据框操作:
data.table提供了对数据框进行高效操作的函数,包括增加、删除、修改、筛选、排序等操作,使得用户可以方便地对数据进行各种处理。数据汇总:
data.table提供了用于数据汇总和聚合的函数,包括by、keyby、summarize等,可以按照指定的变量对数据进行分组,并进行统计汇总操作。数据合并:
data.table支持多种数据合并操作,包括连接、合并、堆叠等,可以方便地将多个数据集进行合并和整合。高性能:
data.table采用了优化的内存管理和算法实现,具有非常高的运行效率和性能,特别适用于大型数据集的处理和分析。支持链式操作:
data.table支持链式操作(chaining),可以将多个操作连接起来,形成一条完整的数据处理流程,使得代码更加简洁清晰。灵活的语法:
data.table提供了简洁而灵活的语法,可以进行复杂的数据操作和变换,支持类似 SQL 的语法和功能,使得用户可以方便地进行数据处理和分析。
总的来说,data.table 是一个功能丰富、高效可靠的数据处理包,为用户提供了丰富的数据处理和操作功能,极大地简化了数据处理和分析的过程,是 R 语言中非常重要的数据处理工具之一。
meta (meta相关)
meta 包是 R 语言中用于执行元分析(meta-analysis)的一个包,它提供了一套丰富的函数和工具,用于整合和分析多个独立研究的结果,从而得出总体效应量的估计和置信区间。meta 包的主要功能和作用包括:
执行固定效应模型和随机效应模型的元分析:
meta包支持执行固定效应模型(fixed-effect model)和随机效应模型(random-effects model)的元分析,可以根据用户的需求选择合适的模型来估计总体效应量。计算加权平均效应量:
meta包可以计算加权平均效应量(weighted mean effect size),并计算置信区间和相应的统计检验,以评估总体效应量的显著性和可靠性。绘制森林图:
meta包提供了绘制森林图(forest plot)的函数,用于可视化展示独立研究的效应量和置信区间,以及总体效应量的估计和置信区间。执行异质性检验:
meta包支持执行异质性检验(heterogeneity test),包括 Q 统计量和 I² 统计量等,用于评估研究间的异质性程度。执行敏感性分析:
meta包提供了执行敏感性分析(sensitivity analysis)的函数,可以评估个别研究对总体效应量的影响程度,排除异常研究并重新进行元分析。执行亚组分析:
meta包支持执行亚组分析(subgroup analysis),可以根据预先定义的变量对研究进行分组,并比较不同亚组之间的效应量差异。支持 Meta-regression:
meta包支持进行 Meta-regression 分析,可以通过加权回归模型探讨研究特征和效应量之间的关系。
总的来说,meta 包是一个功能丰富的元分析工具包,提供了一系列函数和工具,用于整合和分析多个独立研究的结果,评估总体效应量和异质性程度,并探讨研究特征和效应量之间的关系,为研究者提供了一个重要的统计分析工具。
ComplexHeatmap
ComplexHeatmap 是 R 语言中用于创建复杂热图(complex heatmap)的一个包,它提供了丰富的功能和选项,用于可视化高维数据的相关性、聚类、分类等信息。ComplexHeatmap 包的主要功能和作用包括:
创建复杂热图:
ComplexHeatmap包可以创建高度定制化的复杂热图,支持在热图中展示多种类型的数据,包括数值、类别、聚类等信息。支持多种数据类型:
ComplexHeatmap支持处理各种类型的数据,包括数值型数据、因子型数据、二分型数据等,可以根据需要对数据进行预处理和转换。支持多种颜色方案:
ComplexHeatmap提供了丰富的颜色方案和调色板选项,包括连续型颜色映射、离散型颜色映射等,可以根据数据的特点选择合适的颜色方案。支持多种标注和注释:
ComplexHeatmap支持在热图中添加各种标注和注释,包括行、列标签、注释文本、注释图形等,可以帮助用户更清晰地理解数据。支持聚类和排序:
ComplexHeatmap支持对行和列进行聚类和排序,可以根据数据的相似性进行聚类,并在热图中展示聚类结果。支持交互式功能:
ComplexHeatmap支持在热图中添加交互式功能,包括放大、缩小、拖动等,使得用户可以方便地探索数据并进行交互操作。输出高质量图像:
ComplexHeatmap支持将热图输出为高质量的图像文件,包括 PNG、JPEG、PDF 等格式,可以方便地在论文或报告中使用。
总的来说,ComplexHeatmap 包是一个功能强大的复杂热图创建工具,提供了丰富的功能和选项,可以帮助用户创建高度定制化的复杂热图,展示数据的相关性、聚类结构、分类信息等,是数据可视化和分析中非常重要的工具之一。
circlize
circlize 是 R 语言中用于创建环形图(circos plot)的一个包,它提供了丰富的功能和选项,用于可视化环形数据的相关性、分布、关联等信息。circlize 包的主要功能和作用包括:
创建环形图:
circlize包可以创建高度定制化的环形图,支持在环形图中展示多种类型的数据,包括数值、类别、关系等信息。支持多种数据类型:
circlize支持处理各种类型的数据,包括数值型数据、因子型数据、关系型数据等,可以根据需要对数据进行预处理和转换。支持多种布局方式:
circlize提供了多种布局方式和样式选项,包括分区布局、扇形布局、堆叠布局等,可以根据数据的特点选择合适的布局方式。支持多种颜色方案:
circlize提供了丰富的颜色方案和调色板选项,包括连续型颜色映射、离散型颜色映射等,可以根据数据的特点选择合适的颜色方案。支持标注和注释:
circlize支持在环形图中添加各种标注和注释,包括文字标签、注释文本、注释图形等,可以帮助用户更清晰地理解数据。支持交互式功能:
circlize支持在环形图中添加交互式功能,包括放大、缩小、拖动等,使得用户可以方便地探索数据并进行交互操作。输出高质量图像:
circlize支持将环形图输出为高质量的图像文件,包括 PNG、JPEG、PDF 等格式,可以方便地在论文或报告中使用。
总的来说,circlize 包是一个功能强大的环形图创建工具,提供了丰富的功能和选项,可以帮助用户创建高度定制化的环形图,展示数据的相关性、分布、关联等信息,是数据可视化和分析中非常重要的工具之一。
plyr
plyr 是 R 语言中用于数据处理和操作的一个包,它提供了一组函数,用于数据的拆分、应用、组合等操作。plyr 包的主要功能和作用包括:
拆分数据:
plyr提供了split()函数,可以根据指定的条件将数据拆分成多个子集,便于后续的分组操作。应用函数:
plyr提供了apply()函数家族,包括llply()、laply()、ldply()等,用于对数据集中的每个子集应用指定的函数,实现数据的批量处理。组合结果:
plyr提供了combine()函数,用于将处理后的子集结果合并成一个数据集,便于后续的分析和可视化。数据分组:
plyr提供了ddply()、adply()、rdply()等函数,用于对数据进行分组汇总,可以按照指定的变量对数据进行分组,并对每个分组应用指定的函数。数据变换:
plyr提供了mutate()函数,用于对数据进行变换和加工,可以添加新的变量、删除变量、重命名变量等。数据合并:
plyr提供了rbind.fill()、cbind.fill()等函数,用于合并多个数据框,可以将不同数据框中的变量进行合并,并填充缺失值。并行处理:
plyr提供了parallel()函数,可以利用多核处理器进行并行计算,加速数据处理的速度。
总的来说,plyr 包提供了一组强大而灵活的函数,可以简化数据处理和操作的过程,提高数据分析的效率和质量,是 R 语言中非常重要的数据处理工具之一。
mada
mada 是 R 语言中的一个包,用于进行医学诊断准确性分析(Medical Accuracy Diagnostic Analysis)。该包提供了一系列函数和工具,用于评估医学诊断测试的准确性、可靠性和效能。主要功能和作用包括:
ROC 曲线分析:
mada包可以绘制和分析受试者工作特征(Receiver Operating Characteristic, ROC)曲线。ROC 曲线是评估诊断测试准确性的重要工具,通过计算不同判定标准下的敏感性和特异性来描述诊断测试的性能。汇总评估指标:
mada包提供了计算和汇总诊断准确性指标的函数,如敏感性、特异性、阳性似然比、阴性似然比等。这些指标可以帮助研究人员综合评估诊断测试的表现。差异比较:
mada包可以进行不同诊断测试方法之间的比较,帮助确定哪种方法在特定条件下更为有效。绘制和定制图形:
mada提供了多种绘图函数,可以根据用户的需求绘制 ROC 曲线、Forest 图和其他相关图形。模型拟合和评估:
mada包支持将不同的诊断准确性模型应用于数据,并评估这些模型的拟合程度和预测能力。
总的来说,mada 包是一个功能丰富的工具,可用于评估和比较医学诊断测试的准确性和效能,对于医学研究和临床实践中的诊断问题具有重要意义。
shinyMatrix
shinyMatrix 是一个 R 包,用于在 Shiny 应用程序中创建和处理矩阵输入。其主要功能和作用包括:
创建矩阵输入:
shinyMatrix允许您在 Shiny 应用程序中创建具有自定义大小的矩阵输入框。用户可以在这些输入框中填写数据,以便在应用程序中使用。动态添加行列:您可以通过
shinyMatrix在运行时动态添加或删除矩阵的行列。这使得用户能够根据需要动态调整矩阵的大小,以适应不同的数据输入需求。数据验证:
shinyMatrix允许您对用户输入的矩阵数据进行验证。您可以指定数据的格式、范围或其他标准,并向用户显示错误消息,以帮助他们更正无效的输入。可视化编辑:通过
shinyMatrix,您可以创建交互式矩阵编辑器,使用户能够直观地编辑和调整矩阵中的数据。与其他 Shiny 元素集成:
shinyMatrix可以与其他 Shiny 元素(如按钮、滑块、下拉菜单等)无缝集成,以实现更复杂的交互式功能。
总的来说,shinyMatrix 为 Shiny 应用程序提供了一个方便的工具,使您能够轻松地在应用程序中集成矩阵输入功能,并与其他元素和功能进行交互。这使得创建具有矩阵数据输入需求的应用程序变得更加简单和高效。
DT
DT 是 R 语言中的一个包,用于创建交互式的数据表格(data tables)。其主要功能和作用包括:
创建静态数据表格:
DT可以将 R 中的数据转换为 HTML 表格,并在 Shiny 应用程序中显示。这使得用户能够在应用程序中查看和浏览数据。创建交互式数据表格:
DT提供了许多交互式功能,如排序、搜索、过滤、分页等。这使得用户能够方便地对数据进行探索和分析。自定义样式和格式:您可以使用
DT来自定义数据表格的样式和格式,包括表格的颜色、字体、边框等。这使得您能够根据应用程序的设计需求创建各种各样的数据表格。支持大型数据集:
DT支持处理大型数据集,可以在处理大量数据时保持良好的性能和响应速度。与 Shiny 应用程序集成:
DT可以与 Shiny 应用程序无缝集成,您可以将交互式数据表格嵌入到 Shiny 应用程序的 UI 中,并与其他元素和功能进行交互。
总的来说,DT 提供了一个简单而强大的工具,用于在 R 和 Shiny 应用程序中创建和展示交互式的数据表格,帮助用户更轻松地探索和分析数据。
svglite
svglite 是 R 语言中的一个包,用于创建和保存 SVG(可伸缩矢量图形)图像。SVG 是一种基于 XML 的图形格式,具有无损放大、高分辨率和可编辑性等特点。svglite 包的主要功能和作用包括:
创建 SVG 图形:
svglite允许您使用 R 代码创建各种类型的 SVG 图形,包括散点图、折线图、条形图、饼图等。您可以使用常见的 R 绘图函数(如plot()、ggplot2、base绘图函数等)来生成图形,并将其保存为 SVG 格式。高品质输出:SVG 格式是一种矢量图形格式,具有无损放大的特性,因此可以在不损失图像质量的情况下进行放大和缩小。使用
svglite包生成的 SVG 图形具有良好的质量和分辨率,适用于打印和网络应用。可编辑性:SVG 图形可以在任何支持 SVG 格式的编辑器中进行编辑和修改,如 Adobe Illustrator、Inkscape 等。这使得您可以对生成的图形进行进一步的定制和美化。
与其他绘图库集成:
svglite可以与其他 R 绘图库(如ggplot2、plotly、lattice等)无缝集成,使您能够在这些绘图库生成的图形基础上保存为 SVG 格式。跨平台兼容性:SVG 格式是一种开放的标准,受到许多现代 Web 浏览器的支持,因此生成的 SVG 图形可以在各种设备和平台上显示和使用。
总的来说,svglite 提供了一个简单而强大的工具,用于在 R 中创建和保存高品质的 SVG 图形,适用于各种数据可视化和图形展示需求。
metawho
“metawho” 的目标是提供一个简单的 R 实现“荟萃分析方法来识别谁最受益于治疗”(称为 ‘deft’ 方法)的工具。它的功能包括:
- 准备数据:提供了 deft_prepare() 函数来准备数据,特别是针对具有风险比和置信区间的数据。
- 执行 deft 分析:使用 deft_do() 函数执行荟萃分析,并提供了不同分组水平的结果。
- 结果展示:使用 deft_show() 函数展示分析结果,可以展示所有条目或特定分组的结果,并提供了与 metafor 包集成的功能,例如绘制森林图。
总的来说,”metawho” 提供了一套工具,可以帮助研究人员进行荟萃分析,特别是针对具有风险比和置信区间的数据。
统计介绍
风险偏差分析
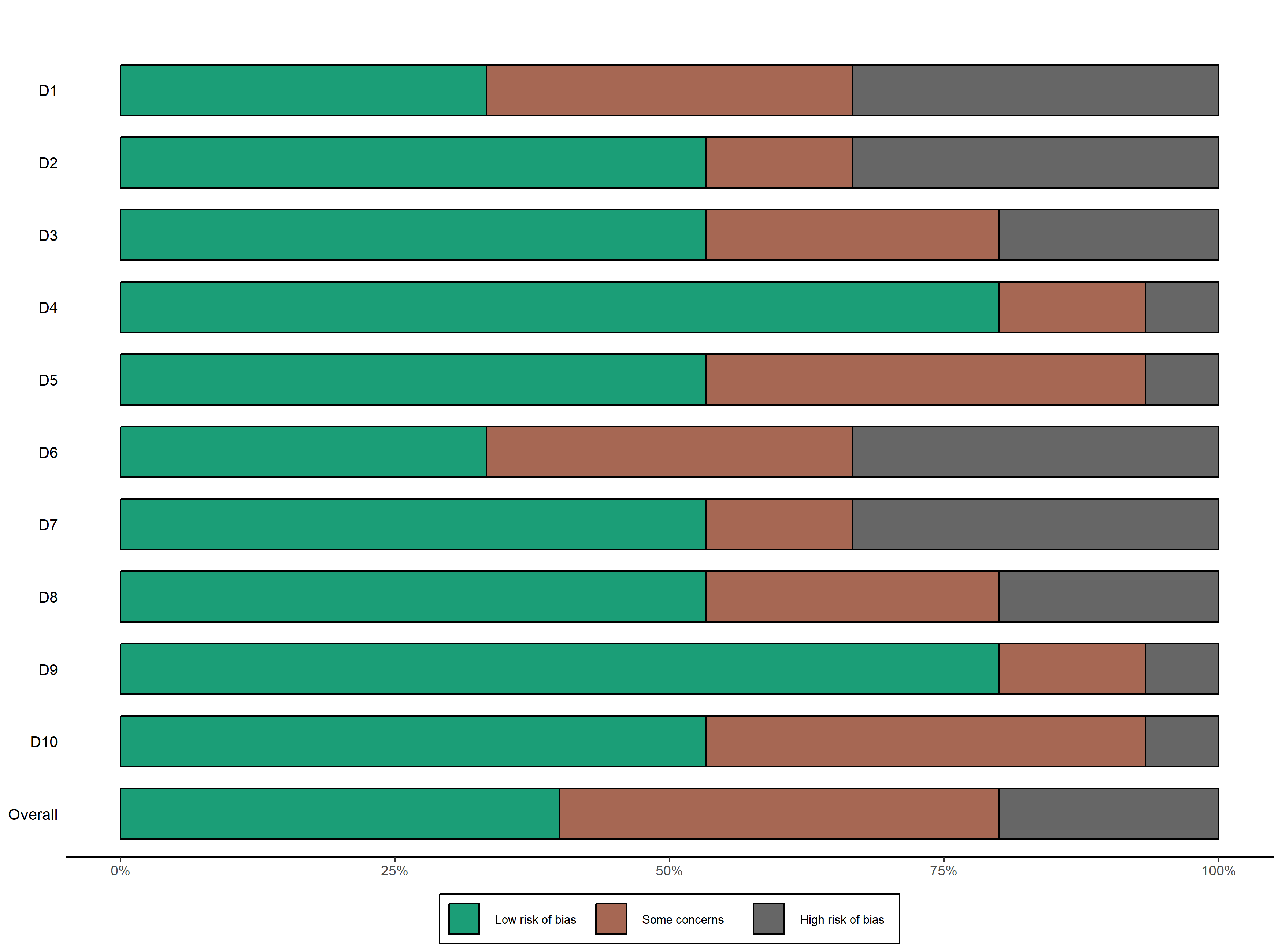
风险偏差直方图
风险偏差直方图可以直观地展示研究之间的差异,这些差异可能是由于患者特征、研究设计或其他因素引起的。通过查看风险偏差直方图,可以了解研究之间的异质性程度,以及这些异质性对荟萃分析结果的影响。
具体来说,风险偏差直方图可以显示每个研究的风险偏差(或其他效果量的估计),以及这些估计的分布情况。通过直观地比较直方图中的柱状图,可以发现一些重要的模式或趋势,例如:
研究之间的异质性: 如果直方图显示了广泛的分布,即柱状图呈现出较宽的形状,这表明研究之间存在显著的异质性。这可能意味着不同研究的研究对象、治疗方法或其他因素存在差异,导致了效果量的差异。
研究的权重: 直方图中的柱状图的高度和密度可以反映每个研究对荟萃分析结果的贡献程度。较高的柱状图表示研究的样本量较大,可能在合成效果量中占据较大的权重。
异常值和离群点: 如果直方图中存在与其他研究明显不同的柱状图,这可能表示该研究的效果量与其他研究有明显的偏离,可能是由于研究设计、数据质量或其他原因导致的异常情况。
总的来说,风险偏差直方图可以帮助研究者快速了解荟萃分析中各个研究之间的差异性和异质性程度,有助于更好地理解荟萃分析结果的稳健性和可靠性。
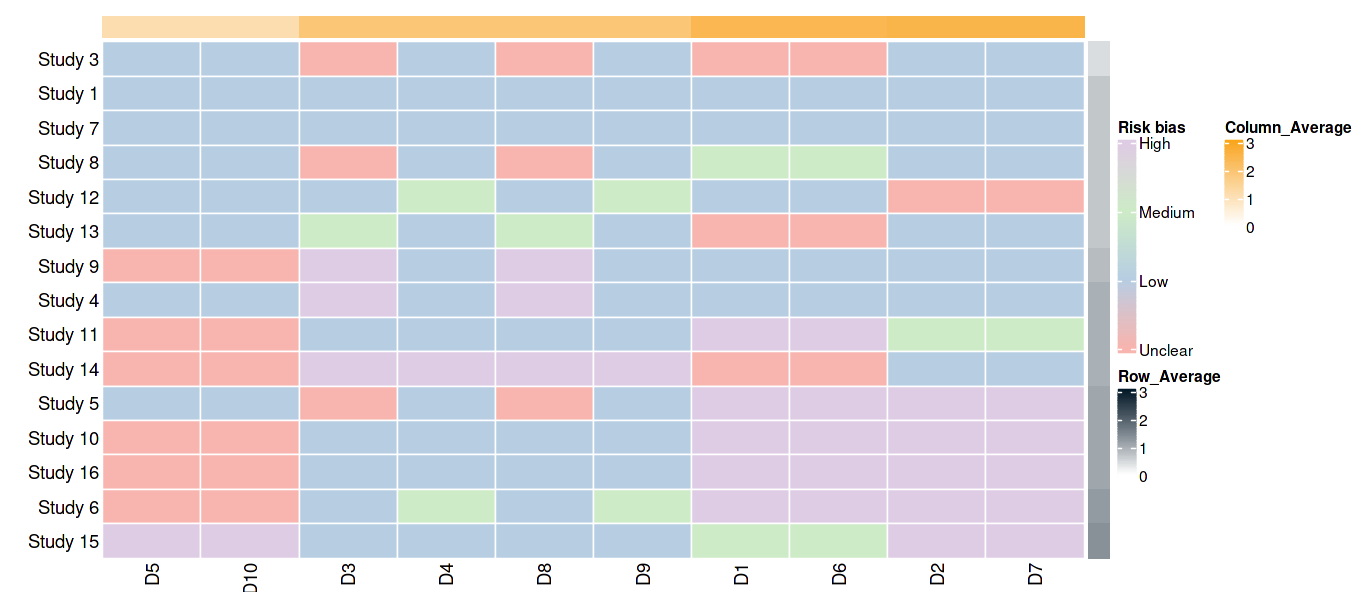
风险偏差热图
风险偏差热图是一种可视化工具,用于展示研究之间的异质性和差异性,特别是在荟萃分析中。它将研究的效果量(例如风险比、风险差或标准化均数差)以矩阵的形式呈现,通过颜色编码来表示不同效果量之间的差异。
以下是风险偏差热图的作用:
可视化效果量差异: 风险偏差热图通过颜色编码反映了不同研究之间效果量的差异性。通常,颜色较深的单元格表示效果量差异较大,而颜色较浅的单元格表示效果量差异较小。
识别异质性: 异质性是指不同研究之间的效果量差异,可能由于研究设计、人群特征或其他因素引起。风险偏差热图可以帮助研究者直观地识别研究之间的异质性程度,从而评估荟萃分析结果的可靠性。
确定高质量证据: 在荟萃分析中,一些研究可能贡献更多的权重,而其他研究可能贡献较少的权重。风险偏差热图可以帮助研究者识别那些在整体效果量中具有较高权重的研究,从而确定哪些研究提供了更可靠的证据。
辅助数据解释和沟通: 风险偏差热图是一种直观的可视化工具,可以帮助研究者和决策者更好地理解荟萃分析结果,并用于数据解释和沟通。它可以用于研究报告、学术文章或决策支持文档中,以帮助读者更好地理解研究结果。
总的来说,风险偏差热图是一种有用的工具,可以帮助研究者快速了解研究之间的异质性和差异性,从而更好地评估荟萃分析结果的可靠性和稳健性。
Meta分析
在学习meta之前,先来学学一些统计概念
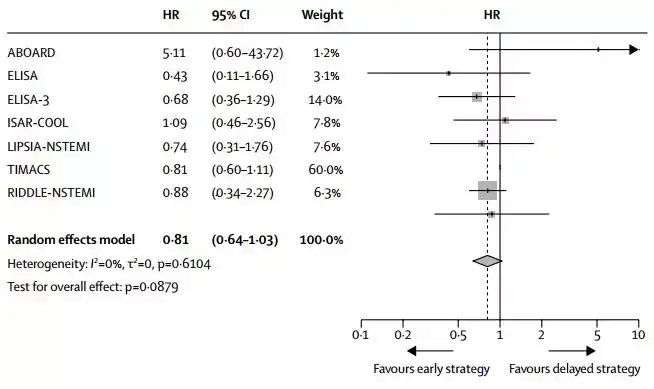
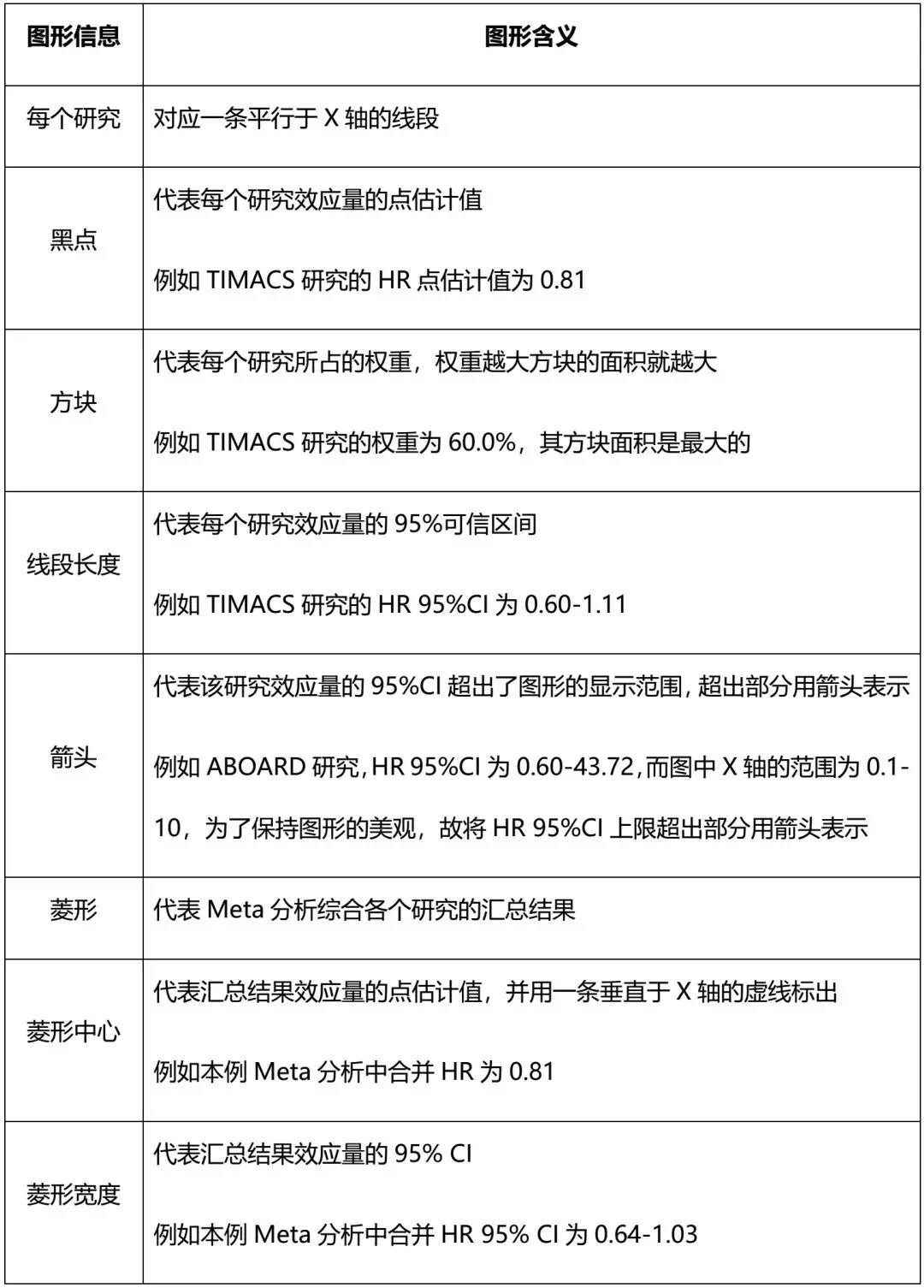
森林图
双臂二分类变量Dichotomous Variable
连续变量Continuous Variable
单臂二分类变量Single Dichotomous Variable
在荟萃分析中,summary measure 是用来汇总多个研究结果的指标,常见的 summary measure 包括 PLOGIT、PAS、PFT、PLN 和 PRAW,它们分别代表不同的汇总指标:
PLOGIT(Log odds ratio):对于二分变量的荟萃分析,常用的汇总指标是 log odds ratio,即对各个研究的二分变量结果取对数后求平均。PLOGIT 是指 Pooled Logit 的缩写,表示采用 log odds ratio 作为汇总指标。
PAS(Risk difference):风险差异是衡量两组之间风险差异的指标,通常是指暴露组与对照组之间的风险差异。PAS 是指 Pooled Absolute Risk Difference 的缩写,表示采用风险差异作为汇总指标。
PFT(Risk ratio):风险比是衡量暴露组与对照组之间相对风险的指标,通常是指两组之间的风险比率。PFT 是指 Pooled Risk Ratio 的缩写,表示采用风险比作为汇总指标。
PLN(Log risk ratio):对数风险比是对风险比进行对数转换后的结果,常用于对风险比进行线性分析。PLN 是指 Pooled Log Risk Ratio 的缩写,表示采用对数风险比作为汇总指标。
PRAW(Raw mean difference):原始均值差是指两组之间的原始均值差异,适用于连续变量的荟萃分析。PRAW 是指 Pooled Raw Mean Difference 的缩写,表示采用原始均值差作为汇总指标。
这些汇总指标在荟萃分析中用于综合多个研究的效应量,从而得出总体效应量的估计结果。选择合适的汇总指标需要根据研究对象、研究设计和数据类型等因素综合考虑。
单个连续变量Single Continuous Variable
单次试验的Deft分析Deft Analysis For Single Trials
单次试验的Deft分析是一种统计方法,用于评估在医学临床试验中,哪些人群从治疗中获益最多。DEFT代表的是“Differential Effectiveness from Treatment”。这种方法通过将个体数据与其相关的特征进行比较,来识别哪些人在特定治疗方案下表现最佳。
在单次试验的Deft分析中,”hr”通常代表”hazard ratio”,即风险比。风险比是生存分析中常用的一种度量,用于比较两组(例如治疗组和对照组)中事件发生的风险。在Deft分析中,风险比通常用于评估不同个体或群体在特定治疗方案下的生存时间或事件发生的风险。
例如,在癌症治疗研究中,可以使用风险比来比较接受不同治疗方案的患者之间癌症复发或死亡的风险。较小的风险比表示治疗组相对于对照组有更低的风险,而较大的风险比表示治疗组相对于对照组有更高的风险。



